Today, I’m extremely happy to announce Amazon SageMaker Pipelines, a new capability of Amazon SageMaker that makes it easy for data scientists and engineers to build, automate, and scale end to end machine learning pipelines.
Machine learning (ML) is intrinsically experimental and unpredictable in nature. You spend days or weeks exploring and processing data in many different ways, trying to crack the geode open to reveal its precious gemstones. Then, you experiment with different algorithms and parameters, training and optimizing lots of models in search of highest accuracy. This process typically involves lots of different steps with dependencies between them, and managing it manually can become quite complex. In particular, tracking model lineage can be difficult, hampering auditability and governance. Finally, you deploy your top models, and you evaluate them against your reference test sets. Finally? Not quite, as you’ll certainly iterate again and again, either to try out new ideas, or simply to periodically retrain your models on new data.
No matter how exciting ML is, it does unfortunately involve a lot of repetitive work. Even small projects will require hundreds of steps before they get the green light for production. Over time, not only does this work detract from the fun and excitement of your projects, it also creates ample room for oversight and human error.
To alleviate manual work and improve traceability, many ML teams have adopted the DevOps philosophy and implemented tools and processes for Continuous Integration and Continuous Delivery (CI/CD). Although this is certainly a step in the right direction, writing your own tools often leads to complex projects that require more software engineering and infrastructure work than you initially anticipated. Valuable time and resources are diverted from the actual ML project, and innovation slows down. Sadly, some teams decide to revert to manual work, for model management, approval, and deployment.
Introducing Amazon SageMaker Pipelines
Simply put, Amazon SageMaker Pipelines brings in best-in-class DevOps practices to your ML projects. This new capability makes it easy for data scientists and ML developers to create automated and reliable end-to-end ML pipelines. As usual with SageMaker, all infrastructure is fully managed, and doesn’t require any work on your side.
Care.com is the world’s leading platform for finding and managing high-quality family care. Here’s what Clemens Tummeltshammer, Data Science Manager, Care.com, told us: “A strong care industry where supply matches demand is essential for economic growth from the individual family up to the nation’s GDP. We’re excited about Amazon SageMaker Feature Store and Amazon SageMaker Pipelines, as we believe they will help us scale better across our data science and development teams, by using a consistent set of curated data that we can use to build scalable end-to-end machine learning (ML) model pipelines from data preparation to deployment. With the newly announced capabilities of Amazon SageMaker, we can accelerate development and deployment of our ML models for different applications, helping our customers make better informed decisions through faster real-time recommendations.”
Let me tell you more about the main components in Amazon SageMaker Pipelines: pipelines, model registry, and MLOps templates.
Pipelines – Model building pipelines are defined with a simple Python SDK. They can include any operation available in Amazon SageMaker, such as data preparation with Amazon SageMaker Processing or Amazon SageMaker Data Wrangler, model training, model deployment to a real-time endpoint, or batch transform. You can also add Amazon SageMaker Clarify to your pipelines, in order to detect bias prior to training, or once the model has been deployed. Likewise, you can add Amazon SageMaker Model Monitor to detect data and prediction quality issues.
Once launched, model building pipelines are executed as CI/CD pipelines. Every step is recorded, and detailed logging information is available for traceability and debugging purposes. Of course, you can also visualize pipelines in Amazon SageMaker Studio, and track their different executions in real time.
Model Registry – The model registry lets you track and catalog your models. In SageMaker Studio, you can easily view model history, list and compare versions, and track metadata such as model evaluation metrics. You can also define which versions may or may not be deployed in production. In fact, you can even build pipelines that automatically trigger model deployment once approval has been given. You’ll find that the model registry is very useful in tracing model lineage, improving model governance, and strengthening your compliance posture.
MLOps Templates – SageMaker Pipelines includes a collection of built-in CI/CD templates for popular pipelines (build/train/deploy, deploy only, and so on). You can also add and publish your own templates, so that your teams can easily discover them and deploy them. Not only do templates save lots of time, they also make it easy for ML teams to collaborate from experimentation to deployment, using standard processes and without having to manage any infrastructure. Templates also let Ops teams customize steps as needed, and give them full visibility for troubleshooting.
Now, let’s do a quick demo!
Building an End-to-end Pipeline with Amazon SageMaker Pipelines
Opening SageMaker Studio, I select the “Components” tab and the “Projects” view. This displays a list of built-in project templates. I pick one to build, train, and deploy a model.

Then, I simply give my project a name, and create it.
A few seconds later, the project is ready. I can see that it includes two Git repositories hosted in AWS CodeCommit, one for model training, and one for model deployment.

The first repository provides scaffolding code to create a multi-step model building pipeline: data processing, model training, model evaluation, and conditional model registration based on accuracy. As you’ll see in the pipeline.py file, this pipeline trains a linear regression model using the XGBoost algorithm on the well-known Abalone dataset. This repository also includes a build specification file, used by AWS CodePipeline and AWS CodeBuild to execute the pipeline automatically.
Likewise, the second repository contains code and configuration files for model deployment, as well as test scripts required to pass the quality gate. This operation is also based on AWS CodePipeline and AWS CodeBuild, which run a AWS CloudFormation template to create model endpoints for staging and production.
Clicking on the two blue links, I clone the repositories locally. This triggers the first execution of the pipeline.
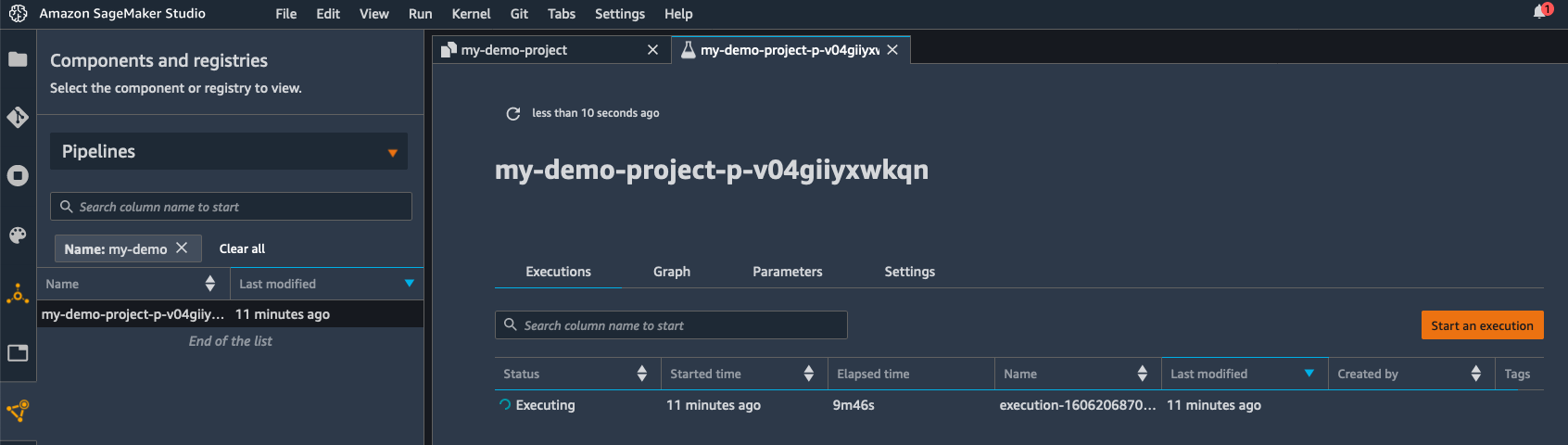
A few minutes later, the pipeline has run successfully. Switching to the “Pipelines” view, I can visualize its steps.

Clicking on the training step, I can see the Root Mean Square Error (RMSE) metrics for my model.
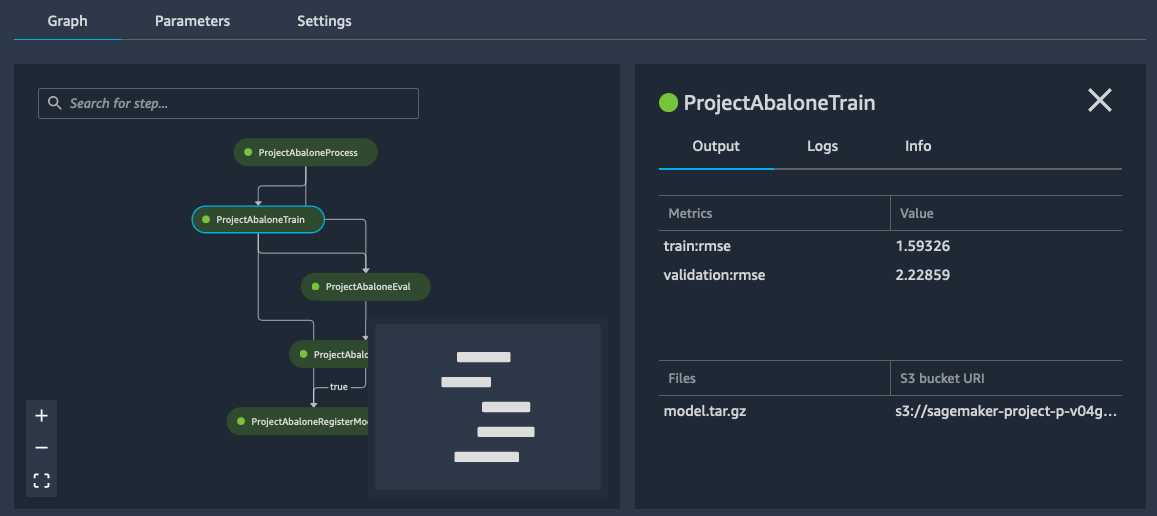
As the RMSE is lower than the threshold defined in the conditional step, my model is added to the model registry, as visible below.
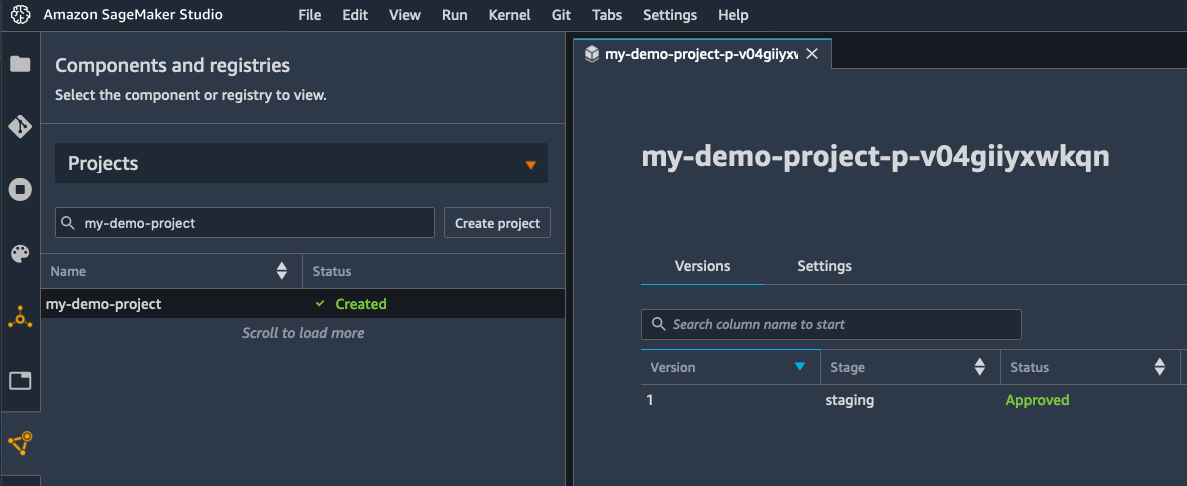
For simplicity, the registration step sets the model status to “Approved”, which automatically triggers its deployment to a real-time endpoint in the same account. Within seconds, I see that the model is being deployed.

Alternatively, you could register your model with a “Pending manual approval” status. This will block deployment until the model has been reviewed and approved manually. As the model registry supports cross-account deployment, you could also easily deploy in a different account, without having to copy anything across accounts.
A few minutes later, the endpoint is up, and I could use it to test my model.

Once I’ve made sure that this model works as expected, I could ping the MLOps team, and ask them to deploy the model in production.
Putting my MLOps hat on, I open the AWS CodePipeline console, and I see that my deployment is indeed waiting for approval.

I then approve the model for deployment, which triggers the final stage of the pipeline.
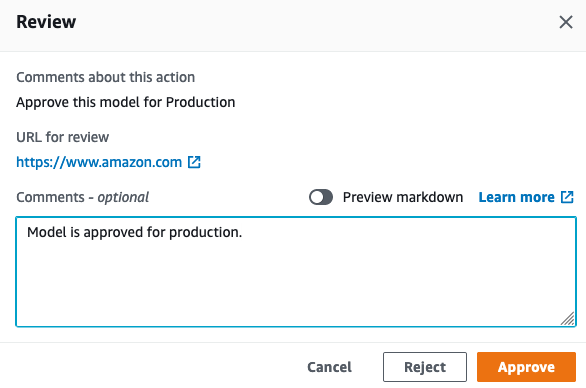
Reverting to my Data Scientist hat, I see in SageMaker Studio that my model is being deployed. Job done!

Getting Started
As you can see, Amazon SageMaker Pipelines makes it really easy for Data Science and MLOps teams to collaborate using familiar tools. They can create and execute robust, automated ML pipelines that deliver high quality models in production quicker than before.
You can start using SageMaker Pipelines in all commercial regions where SageMaker is available. The MLOps capabilities are available in the regions where CodePipeline is also available.
Sample notebooks are available to get you started. Give them a try, and let us know what you think. We’re always looking forward to your feedback, either through your usual AWS support contacts, or on the AWS Forum for SageMaker.
- JulienSpecial thanks to my colleague Urvashi Chowdhary for her precious assistance during early testing.
Via AWS News Blog https://ift.tt/1EusYcK
No comments:
Post a Comment