Healthcare organizations collect vast amounts of patient information every day, from family history and clinical observations to diagnoses and medications. They use all this data to try to compile a complete picture of a patient’s health information in order to provide better healthcare services. Currently, this data is distributed across various systems (electronic medical records, laboratory systems, medical image repositories, etc.) and exists in dozens of incompatible formats.
Emerging standards, such as Fast Healthcare Interoperability Resources (FHIR), aim to address this challenge by providing a consistent format for describing and exchanging structured data across these systems. However, much of this data is unstructured information contained in medical records (e.g., clinical records), documents (e.g., PDF lab reports), forms (e.g., insurance claims), images (e.g., X-rays, MRIs), audio (e.g., recorded conversations), and time series data (e.g., heart electrocardiogram) and it is challenging to extract this information.
It can take weeks or months for a healthcare organization to collect all this data and prepare it for transformation (tagging and indexing), structuring, and analysis. Furthermore, the cost and operational complexity of doing all this work is prohibitive for most healthcare organizations.

Today, we are happy to announce Amazon HealthLake, a fully managed, HIPAA-eligible service, now in preview, that allows healthcare and life sciences customers to aggregate their health information from different silos and formats into a centralized AWS data lake. HealthLake uses machine learning (ML) models to normalize health data and automatically understand and extract meaningful medical information from the data so all this information can be easily searched. Then, customers can query and analyze the data to understand relationships, identify trends, and make predictions.
How It Works
Amazon HealthLake supports copying your data from on premises to the AWS Cloud, where you can store your structured data (like lab results) as well as unstructured data (like clinical notes), which HealthLake will tag and structure in FHIR. All the data is fully indexed using standard medical terms so you can quickly and easily query, search, analyze, and update all of your customers’ health information.

With HealthLake, healthcare organizations can collect and transform patient health information in minutes and have a complete view of a patients medical history, structured in the FHIR industry standard format with powerful search and query capabilities.
From the AWS Management Console, healthcare organizations can use the HealthLake API to copy their on-premises healthcare data to a secure data lake in AWS with just a few clicks. If your source system is not configured to send data in FHIR format, you can use a list of AWS partners to easily connect and convert your legacy healthcare data format to FHIR.
HealthLake is Powered by Machine Learning
HealthLake uses specialized ML models such as natural language processing (NLP) to automatically transform raw data. These models are trained to understand and extract meaningful information from unstructured health data.
For example, HealthLake can accurately identify patient information from medical histories, physician notes, and medical imaging reports. It then provides the ability to tag, index, and structure the transformed data to make it searchable by standard terms such as medical condition, diagnosis, medication, and treatment.
Queries on tens of thousands of patient records are very simple. For example, a healthcare organization can create a list of diabetic patients based on similarity of medications by selecting “diabetes” from the standard list of medical conditions, selecting “oral medications” from the treatment menu, and refining the gender and search.
Healthcare organizations can use Juypter Notebook templates in Amazon SageMaker to quickly and easily run analysis on the normalized data for common tasks like diagnosis predictions, hospital re-admittance probability, and operating room utilization forecasts. These models can, for example, help healthcare organizations predict the onset of disease. With just a few clicks in a pre-built notebook, healthcare organizations can apply ML to their historical data and predict when a diabetic patient will develop hypertension in the next five years. Operators can also build, train, and deploy their own ML models on data using Amazon SageMaker directly from the AWS management console.
Let’s Create Your Own Data Store and Start to Test
Starting to use HealthLake is simple. You access AWS Management Console, and click select Create a datastore.
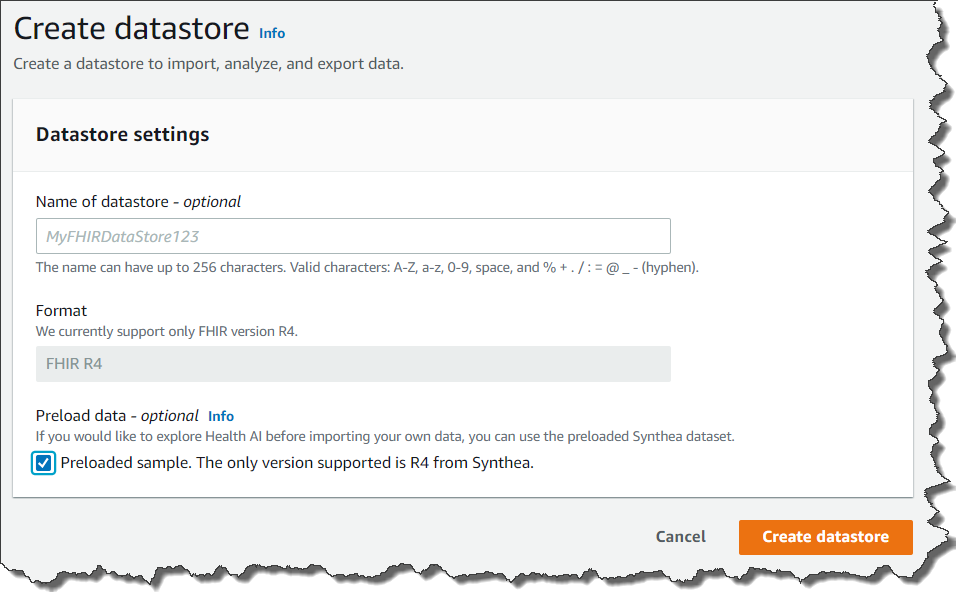 If you click Preload data, HealthLake will load test data and you can start to test its features. You can also upload your own data if you already have FHIR 4 compliant data. You upload it to S3 buckets, and import it to set its bucket name.
If you click Preload data, HealthLake will load test data and you can start to test its features. You can also upload your own data if you already have FHIR 4 compliant data. You upload it to S3 buckets, and import it to set its bucket name.
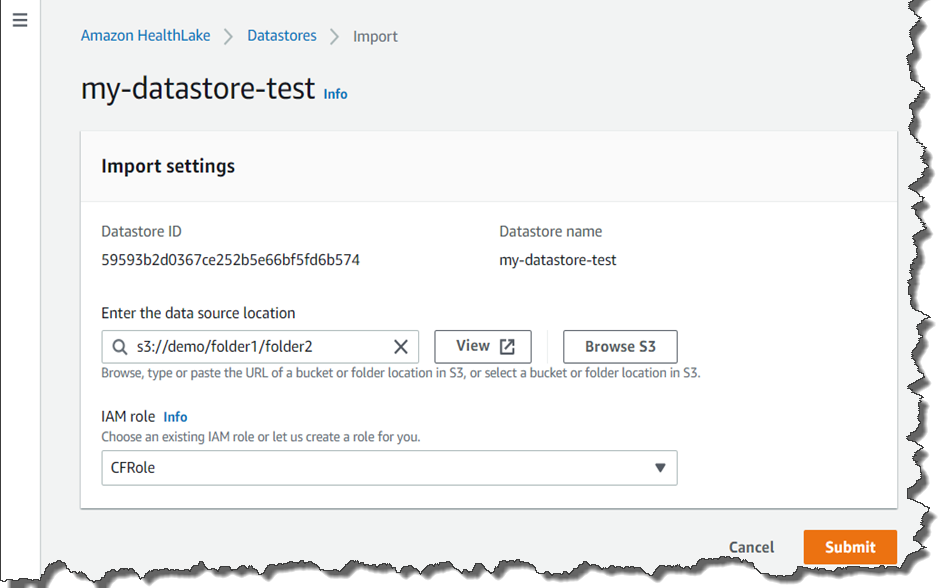
Once your Data Store is created, you can perform a Search, Create, Read, Update or Delete FHIR Query Operation. For example, if you need a list of every patient located in New York, your query setting looks like the screenshots below. As per the FHIR specification, deleted data is only hidden from analysis and results; it is not deleted from the service, only versioned.

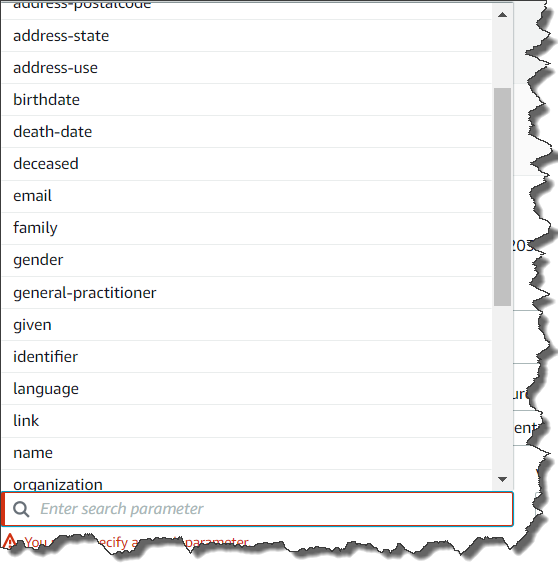
You can choose Add search parameter for more nested conditions of the query as shown below.
Amazon HealthLake is Now in Preview
Amazon HealthLake is in preview starting today in US East (N. Virginia). Please check our web site and technical documentation for more information.
– Kame
Via AWS News Blog https://ift.tt/1EusYcK
No comments:
Post a Comment