Since 2006, Amazon Web Services (AWS) has been helping millions of customers build and manage their IT workloads. From startups to large enterprises to public sector, organizations of all sizes use our cloud computing services to reach unprecedented levels of security, resiliency, and scalability. Every day, they’re able to experiment, innovate, and deploy to production in less time and at lower cost than ever before. Thus, business opportunities can be explored, seized, and turned into industrial-grade products and services.
As Machine Learning (ML) became a growing priority for our customers, they asked us to build an ML service infused with the same agility and robustness. The result was Amazon SageMaker, a fully managed service launched at AWS re:Invent 2017 that provides every developer and data scientist with the ability to build, train, and deploy ML models quickly.

Today, Amazon SageMaker is helping tens of thousands of customers in all industry segments build, train and deploy high quality models in production: financial services (Euler Hermes, Intuit, Slice Labs, Nerdwallet, Root Insurance, Coinbase, NuData Security, Siemens Financial Services), healthcare (GE Healthcare, Cerner, Roche, Celgene, Zocdoc), news and media (Dow Jones, Thomson Reuters, ProQuest, SmartNews, Frame.io, Sportograf), sports (Formula 1, Bundesliga, Olympique de Marseille, NFL, Guiness Six Nations Rugby), retail (Zalando, Zappos, Fabulyst), automotive (Atlas Van Lines, Edmunds, Regit), dating (Tinder), hospitality (Hotels.com, iFood), industry and manufacturing (Veolia, Formosa Plastics), gaming (Voodoo), customer relationship management (Zendesk, Freshworks), energy (Kinect Energy Group, Advanced Microgrid Systems), real estate (Realtor.com), satellite imagery (Digital Globe), human resources (ADP), and many more.
When we asked our customers why they decided to standardize their ML workloads on Amazon SageMaker, the most common answer was: “SageMaker removes the undifferentiated heavy lifting from each step of the ML process.” Zooming in, we identified five areas where SageMaker helps them most.
#1 – Build Secure and Reliable ML Models, Faster
As many ML models are used to serve real-time predictions to business applications and end users, making sure that they stay available and fast is of paramount importance. This is why Amazon SageMaker endpoints have built-in support for load balancing across multiple AWS Availability Zones, as well as built-in Auto Scaling to dynamically adjust the number of provisioned instances according to incoming traffic.
For even more robustness and scalability, Amazon SageMaker relies on production-grade open source model servers such as TensorFlow Serving, the Multi-Model Server, and TorchServe. A collaboration between AWS and Facebook, TorchServe is available as part of the PyTorch project, and makes it easy to deploy trained models at scale without having to write custom code.
In addition to resilient infrastructure and scalable model serving, you can also rely on Amazon SageMaker Model Monitor to catch prediction quality issues that could happen on your endpoints. By saving incoming requests as well as outgoing predictions, and by comparing them to a baseline built from a training set, you can quickly identify and fix problems like missing features or data drift.
 |
Says Aude Giard, Chief Digital Officer at Veolia Water Technologies: “In 8 short weeks, we worked with AWS to develop a prototype that anticipates when to clean or change water filtering membranes in our desalination plants. Using Amazon SageMaker, we built a ML model that learns from previous patterns and predicts the future evolution of fouling indicators. By standardizing our ML workloads on AWS, we were able to reduce costs and prevent downtime while improving the quality of the water produced. These results couldn’t have been realized without the technical experience, trust, and dedication of both teams to achieve one goal: an uninterrupted clean and safe water supply.” You can learn more in this video. |
#2 – Build ML Models Your Way
When it comes to building models, Amazon SageMaker gives you plenty of options. You can visit AWS Marketplace, pick an algorithm or a model shared by one of our partners, and deploy it on SageMaker in just a few clicks. Alternatively, you can train a model using one of the built-in algorithms, or your own code written for a popular open source ML framework (TensorFlow, PyTorch, and Apache MXNet), or your own custom code packaged in a Docker container.
You could also rely on Amazon SageMaker AutoPilot, a game-changing AutoML capability. Whether you have little or no ML experience, or you’re a seasoned practitioner who needs to explore hundreds of datasets, SageMaker AutoPilot takes care of everything for you with a single API call. It automatically analyzes your dataset, figures out the type of problem you’re trying to solve, builds several data processing and training pipelines, trains them, and optimizes them for maximum accuracy. In addition, the data processing and training source code is available in auto-generated notebooks that you can review, and run yourself for further experimentation. SageMaker Autopilot also now creates machine learning models up to 40% faster with up to 200% higher accuracy, even with small and imbalanced datasets.
Another popular feature is Automatic Model Tuning. No more manual exploration, no more costly grid search jobs that run for days: using ML optimization, SageMaker quickly converges to high-performance models, saving you time and money, and letting you deploy the best model to production quicker.
 |
“NerdWallet relies on data science and ML to connect customers with personalized financial products“, says Ryan Kirkman, Senior Engineering Manager. “We chose to standardize our ML workloads on AWS because it allowed us to quickly modernize our data science engineering practices, removing roadblocks and speeding time-to-delivery. With Amazon SageMaker, our data scientists can spend more time on strategic pursuits and focus more energy where our competitive advantage is—our insights into the problems we’re solving for our users.” You can learn more in this case study. |
 |
Says Tejas Bhandarkar, Senior Director of Product, Freshworks Platform: “We chose to standardize our ML workloads on AWS because we could easily build, train, and deploy machine learning models optimized for our customers’ use cases. Thanks to Amazon SageMaker, we have built more than 30,000 models for 11,000 customers while reducing training time for these models from 24 hours to under 33 minutes. With SageMaker Model Monitor, we can keep track of data drifts and retrain models to ensure accuracy. Powered by Amazon SageMaker, Freddy AI Skills is constantly-evolving with smart actions, deep-data insights, and intent-driven conversations.“ |
#3 – Reduce Costs
Building and managing your own ML infrastructure can be costly, and Amazon SageMaker is a great alternative. In fact, we found out that the total cost of ownership (TCO) of Amazon SageMaker over a 3-year horizon is over 54% lower compared to other options, and developers can be up to 10 times more productive. This comes from the fact that Amazon SageMaker manages all the training and prediction infrastructure that ML typically requires, allowing teams to focus exclusively on studying and solving the ML problem at hand.
Furthermore, Amazon SageMaker includes many features that help training jobs run as fast and as cost-effectively as possible: optimized versions of the most popular machine learning libraries, a wide range of CPU and GPU instances with up to 100GB networking, and of course Managed Spot Training which lets you save up to 90% on your training jobs. Last but not least, Amazon SageMaker Debugger automatically identifies complex issues developing in ML training jobs. Unproductive jobs are terminated early, and you can use model information captured during training to pinpoint the root cause.
Amazon SageMaker also helps you slash your prediction costs. Thanks to Multi-Model Endpoints, you can deploy several models on a single prediction endpoint, avoiding the extra work and cost associated with running many low-traffic endpoints. For models that require some hardware acceleration without the need for a full-fledged GPU, Amazon Elastic Inference lets you save up to 90% on your prediction costs. At the other end of the spectrum, large-scale prediction workloads can rely on AWS Inferentia, a custom chip designed by AWS, for up to 30% higher throughput and up to 45% lower cost per inference compared to GPU instances.
 |
Lyft, one of the largest transportation networks in the United States and Canada, launched its Level 5 autonomous vehicle division in 2017 to develop a self-driving system to help millions of riders. Lyft Level 5 aggregates over 10 terabytes of data each day to train ML models for their fleet of autonomous vehicles. Managing ML workloads on their own was becoming time-consuming and expensive. Says Alex Bain, Lead for ML Systems at Lyft Level 5: “Using Amazon SageMaker distributed training, we reduced our model training time from days to couple of hours. By running our ML workloads on AWS, we streamlined our development cycles and reduced costs, ultimately accelerating our mission to deliver self-driving capabilities to our customers.“ |
#4 – Build Secure and Compliant ML Systems
Security is always priority #1 at AWS. It’s particularly important to customers operating in regulated industries such as financial services or healthcare, as they must implement their solutions with the highest level of security and compliance. For this purpose, Amazon SageMaker implements many security features, making it compliant with the following global standards: SOC 1/2/3, PCI, ISO, FedRAMP, DoD CC SRG, IRAP, MTCS, C5, K-ISMS, ENS High, OSPAR, and HITRUST CSF. It’s also HIPAA BAA eligible.
 |
Says Ashok Srivastava, Chief Data Officer, Intuit: “With Amazon SageMaker, we can accelerate our Artificial Intelligence initiatives at scale by building and deploying our algorithms on the platform. We will create novel large-scale machine learning and AI algorithms and deploy them on this platform to solve complex problems that can power prosperity for our customers.” |
#5 – Annotate Data and Keep Humans in the Loop
As ML practitioners know, turning data into a dataset requires a lot of time and effort. To help you reduce both, Amazon SageMaker Ground Truth is a fully managed data labeling service that makes it easy to annotate and build highly accurate training datasets at any scale (text, image, video, and 3D point cloud datasets).
 |
Says Magnus Soderberg, Director, Pathology Research, AstraZeneca: “AstraZeneca has been experimenting with machine learning across all stages of research and development, and most recently in pathology to speed up the review of tissue samples. The machine learning models first learn from a large, representative data set. Labeling the data is another time-consuming step, especially in this case, where it can take many thousands of tissue sample images to train an accurate model. AstraZeneca uses Amazon SageMaker Ground Truth, a machine learning-powered, human-in-the-loop data labeling and annotation service to automate some of the most tedious portions of this work, resulting in reduction of time spent cataloging samples by at least 50%.” |
Amazon SageMaker is Evaluated
The hundreds of new features added to Amazon SageMaker since launch are testimony to our relentless innovation on behalf of customers. In fact, the service was highlighted in February 2020 as the overall leader in Gartner’s Cloud AI Developer Services Magic Quadrant. Gartner subscribers can click here to learn more about why we have an overall score of 84/100 in their “Solution Scorecard for Amazon SageMaker, July 2020”, the highest rating among our peer group. According to Gartner, we met 87% of required criteria, 73% of preferred, and 85% of optional.
Announcing a Price Reduction on GPU Instances
To thank our customers for their trust and to show our continued commitment to make Amazon SageMaker the best and most cost-effective ML service, I’m extremely happy to announce a significant price reduction on all ml.p2 and ml.p3 GPU instances. It will apply starting October 1st for all SageMaker components and across the following regions: US East (N. Virginia), US East (Ohio), US West (Oregon), EU (Ireland), EU (Frankfurt), EU (London), Canada (Central), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Seoul), Asia Pacific (Tokyo), Asia Pacific (Mumbai), and AWS GovCloud (US-Gov-West).
| Instance Name |
Price Reduction |
| ml.p2.xlarge |
-11% |
| ml.p2.8xlarge |
-14% |
| ml.p2.16xlarge |
-18% |
| ml.p3.2xlarge |
-11% |
| ml.p3.8xlarge |
-14% |
| ml.p3.16xlarge |
-18% |
| ml.p3dn.24xlarge |
-18% |
Getting Started with Amazon SageMaker
As you can see, there are a lot of exciting features in Amazon SageMaker, and I encourage you to try them out! Amazon SageMaker is available worldwide, so chances are you can easily get to work on your own datasets. The service is part of the AWS Free Tier, letting new users work with it for free for hundreds of hours during the first two months.
If you’d like to kick the tires, this tutorial will get you started in minutes. You’ll learn how to use SageMaker Studio to build, train, and deploy a classification model based on the XGBoost algorithm.
Last but not least, I just published a book named “Learn Amazon SageMaker“, a 500-page detailed tour of all SageMaker features, illustrated by more than 60 original Jupyter notebooks. It should help you get up to speed in no time.
As always, we’re looking forward to your feedback. Please share it with your usual AWS support contacts, or on the AWS Forum for SageMaker.
- Julien Via AWS News Blog https://ift.tt/1EusYcK










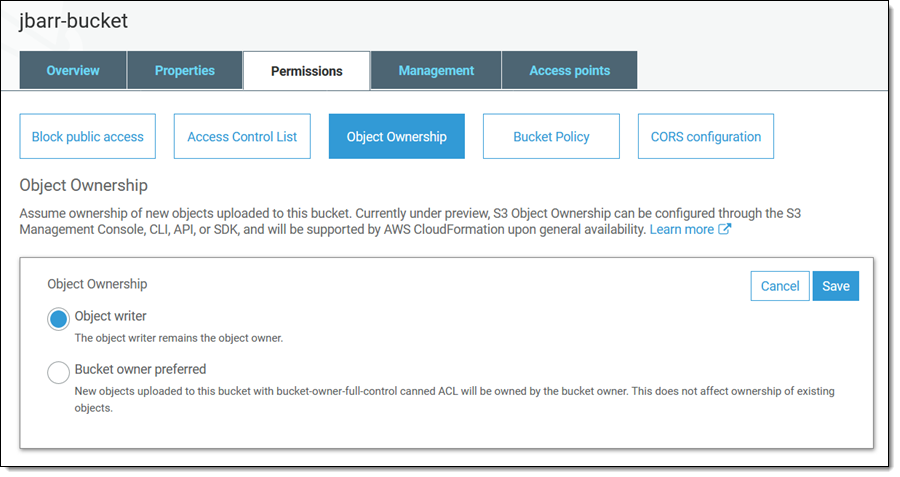
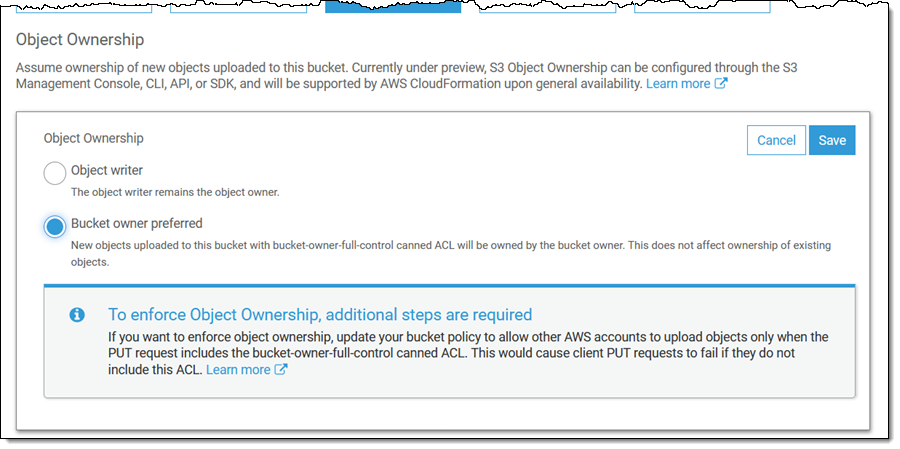
 Today we are launching a preview of
Today we are launching a preview of