What was announced?
We’re announcing the availability of AWS Contact Center Intelligence (CCI) solutions, a combination of services that empowers customers to easily integrate AI into contact centers, made available through AWS Partner Network (APN) partners.
AWS CCI has solutions for self-service, live-call analytics & agent assist, and post-call analytics, making it possible for customers to quickly deploy AI into their existing workflows or build completely new ones.
Pricing and regional availability correspond to the underlying services (Amazon Comprehend, Amazon Kendra, Amazon Lex, Amazon Transcribe, Amazon Translate, and Amazon Polly) used.
What is AWS Contact Center Intelligence?
We mentioned that AWS CCI brings solutions to contact centers powered by AI for before, during, and after customer interactions.
My colleague Swami Sivasubramanian (VP, Amazon Machine Learning, AWS) said: “We want to make it easy for our customers with contact centers to benefit from machine learning capabilities even if they have no machine learning expertise. By partnering with APN technology and consulting partners to bring AWS Contact Center Intelligence solutions to market, we are making it easier for customers to realize the benefits of cloud-based machine learning services while removing the heavy lifting and the need to hire specialized developers to integrate the ML capabilities in to their existing contact centers.”
But what does that mean? 
AWS CCI solutions lets you leverage machine learning (ML) functionality such as text-to-speech, translation, enterprise search, chatbots, business intelligence, and language comprehension into current contact center environments. Customers can now implement contact center intelligence ML solutions to aid self-service, live-call analytics & agent assist, and post-call analytics. Currently, AWS CCI solutions are available through partners such as Genesys, Vonage, and UiPath for easy integration into existing enterprise contact center systems.
“We’re proud Genesys customers will be among the first to benefit from the off-the-shelf machine learning capabilities of AWS Contact Center Intelligence solutions. It’s now simpler and more cost-effective for organizations to combine AWS’s AI capabilities, including search, text-to-speech and natural language understanding, with the advanced contact center capabilities of Genesys Cloud to give customers outstanding self-service experiences.” ~ Olivier Jouve (Executive Vice President and General Manager of Genesys Cloud)
“More and more consumers are relying on automated methods to interact with brands, especially in today’s retail environment where online shopping is taking a front seat. The Genesys Cloud and Amazon Web Services (AWS) integration will make it easier to leverage conversational AI so we can provide more effective self-service experiences for our customers.” ~ Aarde Cosseboom (Senior Director of Global Member Services Technology, Analytics and Product at TechStyle Fashion Group)
How it works and who it’s for…
AWS Contact Center Intelligence solutions offer a variety of ways that organizations can quickly and cost-effectively add machine learning-based intelligence to their contact centers, via AWS pre-trained AI Services. AWS CCI is currently available through participating APN partners, and it is focused on three stages of the contact center workflow: Self-Service, Live Call Analytics and Agent Assist, and Post-Call Analytics. Let’s break each one of these up.
The Self-Service solution helps with creation of chatbots and ML-driven IVRs (Interactive voice response) to address the most common queries a contact center workforce often gets. This now allows actual call center employees to focus on higher value work. To implement this solution, you’ll want to work with either Amazon Lex and/or Amazon Kendra. The novelty of this solution is that Lex + Kendra not only fulfills transactional queries (i.e. book a hotel room or reset my password), but also addresses the long tail of customers questions whose answers live in enterprises knowledge systems. Before, these Q&A had to be hard coded in Lex, making it harder to implement and maintain. Today, you can implement this solution directly from your existing contact center platform with AWS CCI partners, such as Genesys.
The Live Call Analytics & Agent Assist solution enables the creation of real-time ML capabilities to increase staff productivity and engagement. Here, Amazon Transcribe is used to perform real-time speech transcription, while Amazon Comprehend can analyze interactions, detect the sentiment of the caller, and identify key words and phrases in the conversation. Amazon Translate can even be added to translate the conversation into a preferred language! Now, you can implement this solution directly from several leading contact center platforms with AWS CCI partners, like SuccessKPI.
The Post-Call Analytics solution is an automatic analysis of contact center conversations, which tend to leave actionable data for product and service feedback loops. Similar to live call analytics, this solution combines Amazon Transcribe to perform speech recognition and creates a high-quality text transcription of each call, with Amazon Comprehend to analyze the interaction. Amazon Translate can be added to translate the conversation into your preferred language, and Amazon Kendra can be used for contextual natural language queries. Today, you can implement this solution directly from several leading contact center platforms with AWS CCI partners, such as Acqueon.
AWS helps partners integrate these solutions into their products. Some solutions also have a Quick Start, which includes CloudFormation templates and deployment guide, to automate the deployments. The good news is that our AWS Partners landing pages will also provide additional implementation information specific to their products. 
Let’s see a demo…
For today’s post, we chose to focus on diving deeper into the Self-Service and Post-Call Analytics solutions, so let’s begin with Self-Service.
Self-Service
We have a public GitHub repository that has a complete Quick Start template plus a detailed deployment guide with architecture diagrams. (And the good news is that our APN partner landing pages will also reference this repo!)
This GitHub repo talks about the Amazon Lex chatbot integration with Amazon Kendra. The main idea here is that the customer can bring their own document repository through Amazon Kendra, which can be sourced through Amazon Lex when customers are interacting with this Lex chatbot.
The main thing we want to notice in this architecture is that customers can bring their existing documents and allow their chatbot to search that document whenever someone interacts with said chatbot. The architecture below assumes our docs are in an S3 bucket, but it’s worth noting that Amazon Kendra can integrate with multiple kinds of data sources. If using an S3 bucket, customers must provide their own S3 bucket name, the one that has their document repository. This is a prerequisite for deployment.

Let’s follow the instructions under the repo’s Deployment Steps, skipping ahead to Step #2, “Click Deploy to launch the CloudFormation template.”
Since this is a Quick Start template, you can see how everything is already filled out for us. We click Next and move on to Step 2, Specify stack details.

Notice how the S3 bucket section is blank. You can provide your own S3 bucket name if you want to test this out with your own docs. For today, I am going to use the S3 bucket name that was provided to us in the GitHub doc.


The next part to configure will be the Cross account role configuration section. For my demo, I will add my own AWS account ID under “Assuming Account ID.”

We click Next and move on to Step 3, Configure Stack options.

Nothing to configure here, so we can click Next again and move on to Step 4, Review. We click to accept these final acknowledgements and click Create Stack.

If we were to navigate over to our deployed AWS CloudFormation stacks, we can go to Outputs of this stack and see our Kendra index name and Lex bot name.

Now if we head over to Amazon Lex, we should be able to easily find our chatbot.

We click into it and we can see that our chatbot is ready. At this point, we can start interacting with it!

We can something like “Hi” for example.

Eventually we would also get a response that details the reply source. What this means is that it will tell you if this came from Amazon Lex or from Amazon Kendra and the documents we saved in our S3 bucket.
Live Call Analytics & Agent Assist
We have two public GitHub repositories for this solution too, and both have detailed deployment guide with architecture diagrams as well.
This GitHub repo provides us a code example and a fully functional AWS Lambda function to get you started with capturing and transcribing Amazon Chime Voice Connector phone calls using Amazon Kinesis Video Streams and Amazon Transcribe. This solution gives us the ability to see how to use AI and ML services to talk to the customer’s existent environment, to drive agent assistance or analytics. We can take a real-time voice feed, transcribe that information, and then use Amazon Comprehend to pull that information out to provide the key action and sentiment.
We now also provide the Chime SIP req connector (a chime component that allows you to connect voice over an IP compatible environment with Amazon voice services) to stream voice in Amazon Transcribe from virtually any contact center. Our partner Vonage can do the same through websocket.
 Check out the GitHub developer docs:
Check out the GitHub developer docs:
And as we mentioned above, for today’s post, we chose to focus on diving deeper into the Self-Service and Post-Call Analytics solutions. So let’s move on to show an example for Post-Call Analytics.
Post-Call Analytics
We have a public GitHub repository for this solution too, with another complete Quick Start template and detailed deployment guide with architecture diagrams. This solution is used after the call has ended, so that our customers can review the analytics of those calls.
This GitHub repo talks about how to look for insights and information about calls that have already happened. We call this, Quality Management. We can use Amazon Transcribe and Amazon Comprehend to pull out key words, information, and data, in order to know how to better drive what is happening in our contact center calls. We can then review these insights on Amazon QuickSight.
Let’s look at the architecture diagram for this solution too. Our call recording gets stored in an S3 bucket, which is then picked up by a Lambda function which does a transcription using Amazon Transcribe. It puts the result in a different bucket and then that call’s metadata gets stored in DynamoDB. Now Amazon Comprehend can conduct text analysis on the call’s metadata, and stores the result in a Text analysis Output bucket. Eventually, QuickSight is used to provide dashboards showing the resulting call analytics.

Just like in the previous example, we move down to the Deployment steps section. Just like before, we have a pre-made CloudFormation template that is ready to be deployed.
Step 1, Specify template is good to go, so we click Next.

In Step 2, Specify stack details, something important to note is that the User Pool Domain Name must be globally unique.

We click Next and move on to Step 3, Configure Stack options. Nothing additional to configure here either, so we can click Next again and move on to Step 4, Review.
We click to accept these final acknowledgements and click Create Stack.
And if we were to navigate over to our deployed AWS CloudFormation stacks again, we can go to Outputs of this stack and see the PortalEndpoint key. After the stack creation has completed successfully, and portal website is available at CloudFront distribution endpoint. This key is what will allow us to find the portal URL.

We will need to have user created in Amazon Cognito for the next steps to work. (If you have never created one, visit this how-to guide.)
 NOTE: Make sure to open the portal URL endpoint in a different Incognito Window as the portal attaches a QuickSight User Role that can interfere with your actual role.
NOTE: Make sure to open the portal URL endpoint in a different Incognito Window as the portal attaches a QuickSight User Role that can interfere with your actual role.
We go to the portal URL and login with our created Cognito user. We’re prompted to change the temporary password and are eventually directed to the QuickSight homepage.

Now we want to upload the audio files of our calls and we can do so with the Upload button.
After successfully uploading our audio files, the audio processing will run through transcription and text analysis. At this point we can click on the Call Analytics logo in the top left of the Navigation Bar to return to home page.

Now we can drill down into a call to see Amazon Comprehend’s result of the call classifications and turn-by-turn sentiments.
 Lastly…
Lastly…
Regional availability for AWS Contact Center Intelligence (CCI) solutions correspond to the underlying services (Amazon Comprehend, Amazon Kendra, Amazon Lex, Amazon Transcribe, Amazon Translate) used.
We are announcing AWS CCI availability with 12 APN partners: Genesys, UiPath, Vonage, Acqueon, SuccessKPI, and Inference Solutions (Technology partners), and Slalom, Onica/Rackspace, TensorIoT, Quantiphi, Accenture, and HGS Digital (Consulting partners).
Ready to get started? Contact one of the AWS CCI launch partners listed on the AWS CCI web page.
You may also want to see…
AWS Quick Start links from post:
¡Gracias por tu tiempo!
~Alejandra 
 y Canela
y Canela 
Via AWS News Blog https://ift.tt/1EusYcK






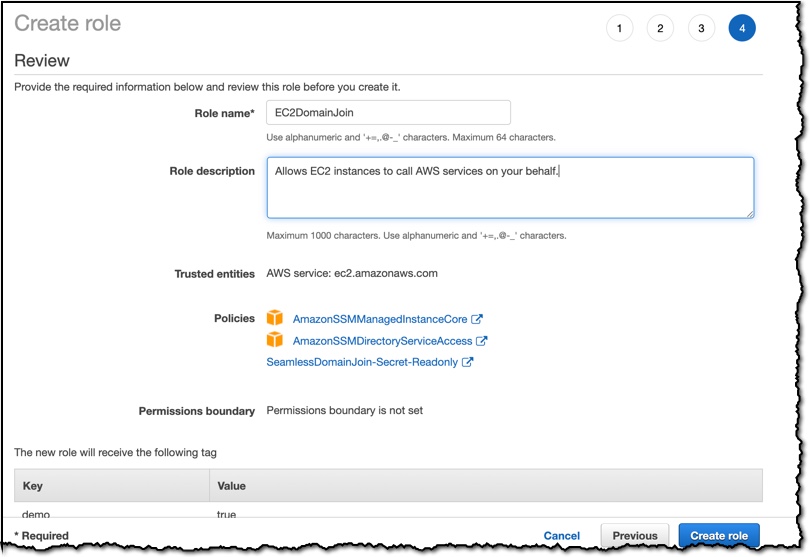



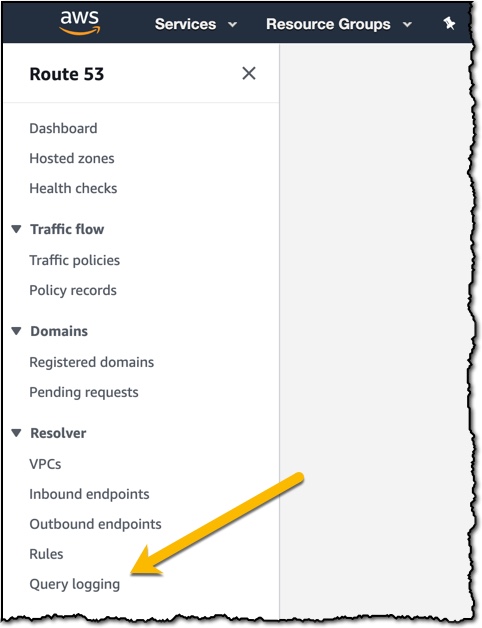
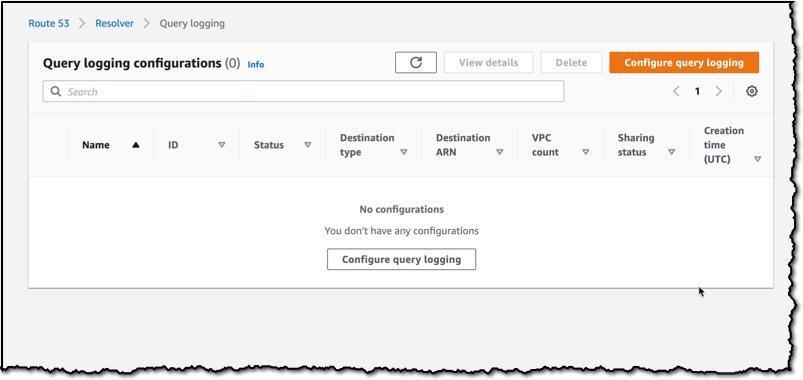

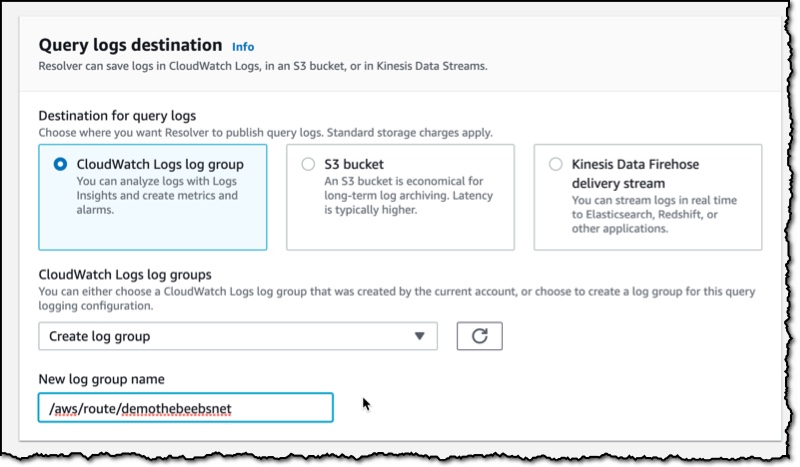
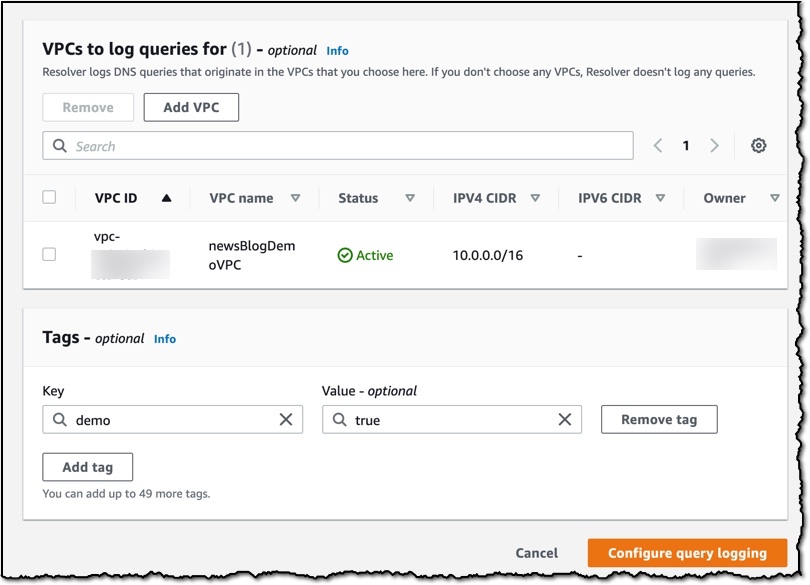

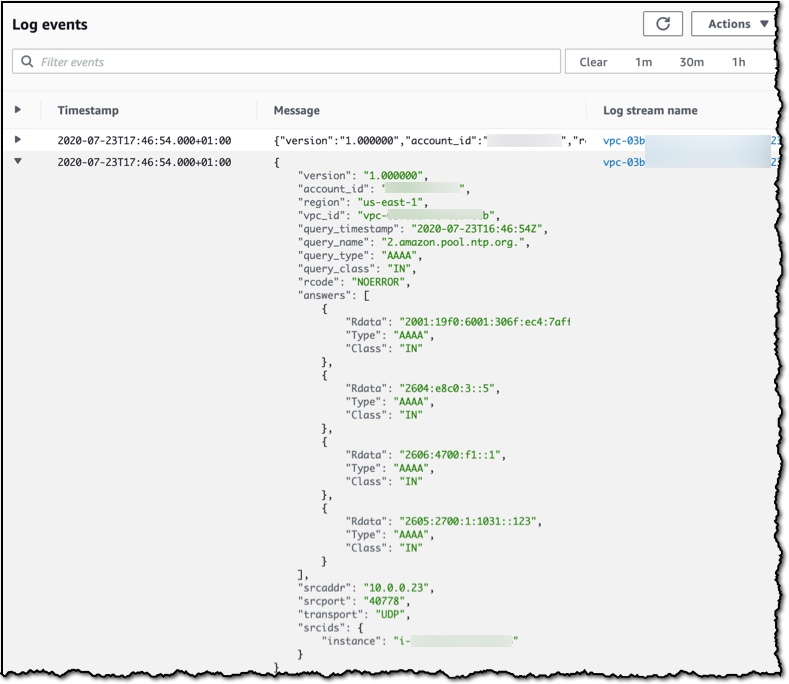
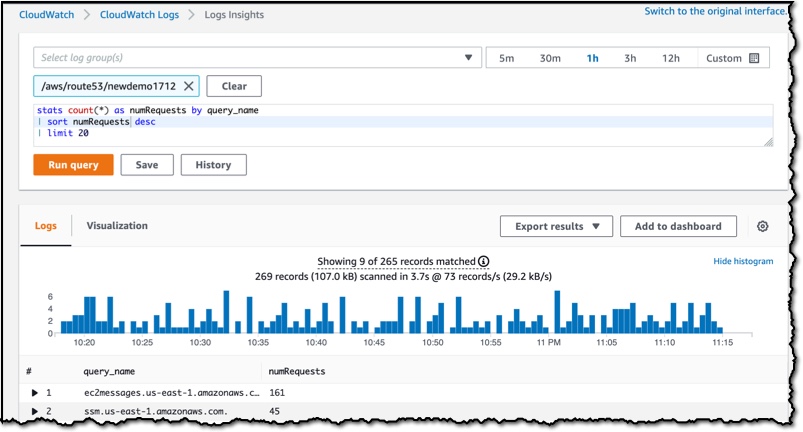
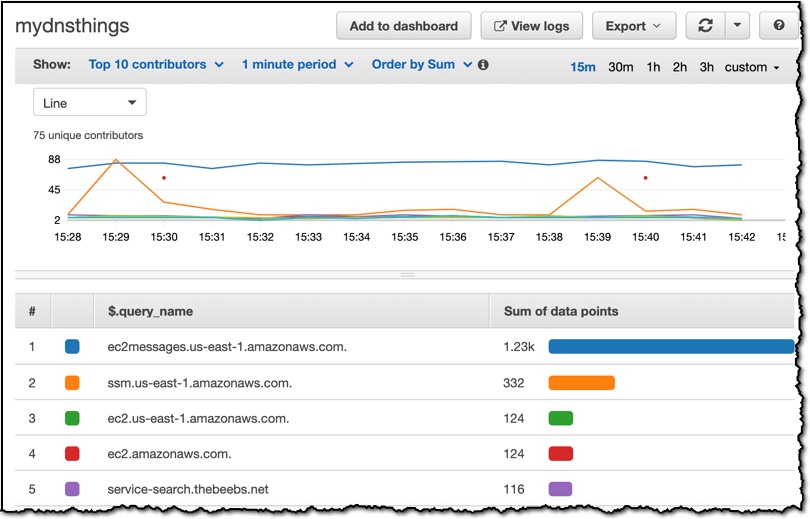 Route 53 Resolver Query Logs is available in all AWS Commercial Regions that support Route 53 Resolver Endpoints, and you can get started using either the API or the AWS Console. You do not pay for the Route 53 Resolver Query Logs, but you will pay for handling the logs in the destination service that you choose. So, for example, if you decided to use
Route 53 Resolver Query Logs is available in all AWS Commercial Regions that support Route 53 Resolver Endpoints, and you can get started using either the API or the AWS Console. You do not pay for the Route 53 Resolver Query Logs, but you will pay for handling the logs in the destination service that you choose. So, for example, if you decided to use